Lesson 6 データ型(リスト/タプル/辞書/各種オブジェクト) ― Python基礎文法入門:機械学習&ディープラーニング入門(Python編)
Python言語の文法を、コードを書く流れに沿って説明していく連載。前回と今回は、値やデータの型を説明。今回はその後編として、list型/tuple型/dict型、それら以外のオブジェクトの型を取り上げる。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
前回は、基本的なデータの型である「bool型(ブール型)」「int型/float型(数値型)」「str型(文字列型)」について解説した。今回は、その後編として「list型(リスト型)」「tuple型(タプル型)」「dict型(辞書型)」、それら以外のモジュールや何らかのオブジェクトの型について説明する。※脚注や図、コードリストの番号は前回からの続き番号としている。
本連載は、実際にライブラリ「TensorFlow」でディープラーニングのコードを書く流れに沿って、具体的にはLesson 1で掲載した図1-a/b/c/dのサンプルコードの順で、基礎文法が学んでいけるように目次を構成している。今回は、図1-a/b/d内の一部コードを取り上げる。



今回、本稿で説明するのは、図1-a/b/d【再掲】における赤枠内のコードのみとなる。青枠内のコードは前回説明した内容となる。
なお、本稿で示すサンプルコードの実行環境については、Lesson 1を一読してほしい。
Lesson 1でも示したように、本連載のすべてのサンプルコードは、下記のリンク先で実行もしくは参照できる。


Python言語の基礎文法
それでは、list型/tuple型/dict型を順に説明していこう。なお今回は、説明すべき文法要素が多く、これまでよりも少し長めの記事となっている。
データの型(コレクション編)
変数には、前回Lesson 4で見たような「モジュール」だけでなく、「数値」「文章」「一覧データ」など、さまざまな値/データが代入できる。例えばリスト8は、前掲の図1-b/d内のサンプルコードの中にある「変数に対して何かを代入している行」(=冒頭で示した【再掲】画像の赤枠の内容)の中から、list型/tuple型/dict型に関するものだけを抜き出して並べたものだ。
#import tensorflow as tf
#mnist = tf.keras.datasets.mnist
# 以下のコードを動かすためには、上記2行を事前に実行しておく必要がある
#---------------------------------------------------------------------
# 変数への「タプル値」の代入
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 「タプル」の構文を応用して、複数の変数にまとめて代入
x_train, x_test = x_train / 255.0, x_test / 255.0
# 以下は「タプル」の構文を応用する同じ方法なので説明を省略
# predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
この例では、主にタプル値のデータ/値が変数に代入されている。
前回説明したbool型/int型/float型/str型は、単一のデータを表現するための型だった。一方、今回説明する下記の3つの型は、複数のデータをまとめて扱うための組み込み型(コレクションもしくはコンテナーと呼ばれる)である(※組み込み型はこれですべてではなく、今回紹介する分のみを記載している)。
- list型: [0.0, 1.2, -1.2]のように、複数の値をまとめたリスト(=一覧データ)値。リスト型
- tuple型: ('Yamada','Taro')のように、複数の値をまとめたタプル(=組データ)値。タプル型
- dict型: {'a': 2.5, 'b': 1.4 }のように、複数の「キー(key):値(value)」のセット値をまとめたディクショナリ値。辞書型
それぞれ具体的なコードで示しながら説明していこう。ちなみにset型(集合型)というコレクションもあるが、これは機械学習では比較的出番が少ないので、本稿では説明を割愛する。
list型(リスト型)
list型は前掲のリスト8には含まれていなかったので、ここでは仮のサンプルコードを提示する(リスト8-1)。
abc_list = ['a', 'b', 'c', 'd', 'e']
abc_list # ['a', 'b', 'c', 'd', 'e']と出力される
変数への「リスト値」の代入をイメージ化すると、図10-1のようになる(※前回の絵と大差ないが、値の部分の表現が少し変わっている)。このようにリストは、複数の値が1列に順に並んでひとまとめになったものをイメージするとよい。

このコード例では、変数abc_listに、「'a'、'b'、'c'、'd'、'e'」という5個の文字列をまとめたリスト値を設定(=代入)している。
このようにリストは、角括弧[〜]で挟んで記述する。括弧の中はカンマ','で区切る(※括弧やカンマの間にある半角スペースはあってもなくてもよいが、一般的にはカンマの後に半角スペースを1つ入れる)。ここでは'a'などの文字列値にしているが、個々の値(=オブジェクト)の型は何でもよい。
機械学習/ディープラーニングのデータは、数学計算のためにもまとめて扱って管理する必要があるので、このリスト型(あるいはリストと同様に扱えるライブラリ「NumPy」のの配列など)を多用する。よってリスト型については、特によく理解しておく必要がある。より深しい内容を、『機械学習&ディープラーニング入門(データ構造編)』で説明しているので、併せて参照してほしい。
◇ インデクシング(要素データの取得)
前回説明したbool型/int型/float型/str型は単一のデータだったので、変数からデータを取得する場合は、単に変数名を書くだけだった。それらと違って、コレクションの場合は、複数のデータがまとまったコレクションの中から、単一のデータを取り出さなければならない場面がある。その取り出し方法(インデクシングと呼ぶ)について簡単に説明しておこう。
list型の場合は、変数名の後に続けた角括弧[〜]の中にインデックス番号(後述)を記載して、取り出すことになる。インデックス番号(index)とは、0からスタートして、1、2、3……と並ぶ整数値のことで、「リストの要素数分」(つまり0〜「リスト要素数 - 1」)の整数値が使える。例えば先ほどの変数abc_listであれば、「'a'のインデックス番号=0からスタートして、'b'のインデックス番号=1、'c'のインデックス番号=2、'd'のインデックス番号=3、'e'のインデックス番号=4」となる(図10-2)。
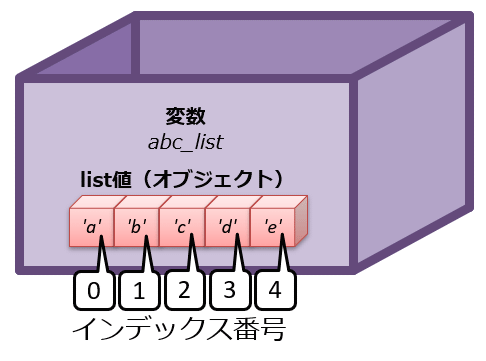 図10-2 リストのインデックス番号
図10-2 リストのインデックス番号 例を挙げると、変数abc_listに代入されているlist型オブジェクトから'b'という要素データを取り出したいのであれば、リスト8-2のように、変数名abc_listの後に続けた角括弧[〜]の中にインデックス番号の1を記載すればよい。
abc_list[1]
# 'b'と出力される
ちなみに、前掲のリスト8にpredictions_array[i]やtrue_label[i]というコードも含まれていたが、これらは厳密にはリストではなく、ライブラリ「NumPy」の多次元配列(ndarray型のオブジェクト)である。ndarrayは、リストと同じようにインデクシングすることができる。つまりpredictions_array[i]やtrue_label[i]というコードもリスト8-2と同じことを行っているというわけだ。
整数値ではなく変数名のiが記載されているが、このiには0や1などの整数値が代入されているのだ。インデックス番号を表す変数の名前は、「index」の頭文字からiと命名することが慣例となっているので覚えておいてほしい。
インデクシングは代入にも応用できる。例えばリスト8-3のように、abc_list[1]というコードで取得した個別要素に対して、数値や文字列などのオブジェクトを代入することで、その要素のみを変更することもできる。
abc_list[1] = 'x'
abc_list # ['a', 'x', 'c', 'd', 'e']と出力される
◇ スライシング(範囲データの取得)
単一のデータだけではなく、範囲指定で複数のデータを取得(=スライス)する方法(スライシングと呼ぶ)についても簡単に説明しておこう。例えば、インデックス番号2〜3の2つ(=list型オブジェクトになる)を取得したい場合は、リスト8-4のように記述すればよい。
abc_list[2:4]
# ['c', 'd']と出力される
コード例から推測できると思うが、角括弧[〜]の中に記載する範囲指定は、
<開始インデックス番号>:<終了インデックス番号>
という仕様になっている。「あれ、2〜3のはずが、2:4という記述になっている」という点に気付いた人は鋭い。<終了インデックス番号>の要素自体は、抽出範囲に含まれないことに注意が必要だ。さらに以下の応用テクニックもある。
応用テクニック1: <開始インデックス番号>を省略して、例えばabc_list[:4]と記述すると、「先頭からインデックス3までを取得」という意味になり、['a', 'x', 'c', 'd']が取得できる(リスト8-4-1)。
abc_list[:4] # 先頭からインデックス3までを取得
# ['a', 'x', 'c', 'd']と出力される
応用テクニック2: <終了インデックス番号>を省略して、例えばabc_list[2:]と記述すると、「インデックス2から末尾までを取得」という意味になり、['c', 'd', 'e']が取得できる(リスト8-4-2)。
abc_list[2:] # インデックス2から末尾までを取得+
# ['c', 'd', 'e']と出力される
応用テクニック3: <開始インデックス番号>:<終了インデックス番号>:<何個先ごと>という構文を使って、例えばabc_list[::2]と記載すると、「先頭から末尾まで2個先ごとに取得」という意味になり、['a', 'c', 'e']が取得できる(リスト8-4-3)。<何個先ごと>に2を指定しており、'a'の1個先が'x'で、2個先が'c'なので、次の取得値は'c'となる。その次は'd'を飛ばして'e'となるため、このようなリスト値が取得できるというわけだ。
abc_list[::2] # 先頭から末尾まで2個先ごとに取得
# ['a', 'c', 'e']と出力される
list型であるリストに関しては、リストの操作(要素の追加や削除、連結、ソート、コピーなど)系の関数があり、特定の場面ではよく使うのですべて紹介したいところだが、本連載は「TensorFlowチュートリアルの読み書き」にフォーカスを当てており、それらについてはあまり出番がないようだったので割愛する。
tuple型(タプル型)
次にtuple型は、前掲のリスト8に含まれていたが少し複雑なので、まずはシンプルな仮のサンプルコードで説明しよう(リスト8-5、図10-3)。
# タプル値は1つの変数に代入できる
tuple_data = ('Taro', 'Yamada')
# 丸括弧を省略して「tuple_data = 'Taro', 'Yamada'」と記述しても同じ意味
tuple_data # ('Taro', 'Yamada')と出力される

リスト8-5では、変数tuple_dataに、「'Taro'」と「'Yamada'」という2つの値を「1つの値」にパックした(=まとめた)タプル値を代入している。
このようにタプルは、丸括弧(〜)で挟んで記述する。括弧の中はカンマ','で区切る。個々の値の型は何でもよい。
タプルの作成方法は、基本的にはリストと同じである。もちろん違う部分もある。特にリストと違うのは、丸括弧(〜)は(見やすさなど必要に応じて)省略できるという点だ。具体的には('Taro', 'Yamada')の代わりに'Taro', 'Yamada'と記述してもよい(後述のリスト8-7で再度説明する)。
◇ リストとタプルの使い分け指針
リストは、データコレクションへの新たなデータの追加や削除ができる(この性質をミュータブルと呼ぶ)ので、大量のデータを取り扱うのには便利である。ひと言でいうと「データのリスト化」(=一覧データにすること)が得意である。
それに対してタプルは、動的にデータコレクションを追加・削除して変更する方法は提供されておらず(この性質をイミュータブルと呼ぶ)、2〜10個など比較的少ない個数分の値を「1つの値」のようにパックにして取り扱いたい際に便利である。ひと言でいうと「複数の値のグループ化」が得意ということだ。
これを聞いても「タプルの使いどころがよく分からない」という意見・感想は多いが、冒頭のリスト8で示したTensorFlowチュートリアルからのコードの抜粋でも分かるように、現場ではタプルは多用されている。タプルの良さはプログラミングを進めると分かってくるので、さらにタプルの特徴的な機能を紹介していこう。特に、次に説明するアンパック代入は、プログラミングをするうえで非常に便利である。実際に、冒頭のリスト8にある「タプル関連の行」のすべてがアンパック代入である。
◇ アンパック代入(複数の変数への分解代入)
タプル(=tuple型のオブジェクト)を分解して、複数の変数に代入することをアンパックもしくはアンパック代入と呼ぶ。
前掲のリスト8の説明に入る前に、ここでは余計な文法機能を含めない仮のサンプルコードを提示する(リスト8-6、図10-4)。
# 変数「tuple_data」の宣言とタプル値の代入は、リスト8-5で行っている
# tuple型で宣言した複数の変数に、タプル値をアンパック代入(=分解して代入)
(first_name, family_name) = tuple_data
family_name # 'Yamada'と出力される

リスト8-6のコード内容を説明すると、tuple_dataは、('Taro', 'Yamada')という値を持つタプルである。そのタプルの各要素を代入される側の変数群は、(first_name, family_name)となっている。
変数群の書き方は、タプルの作成方法とまったく同じである。当然ではあるが、代入元となるタプルの構造(この例では、2つの要素がある)と、代入先にある変数群の構造(この例では、2つの要素がある)は、完全に一致させる必要がある(この例では、どちらも2つの要素で一致している)。その構造に基づき、1つ目の変数には、タプル内にある1番目のオブジェクトが代入され、2つ目の変数にはタプル内2番目のオブジェクトが代入される。
その結果、図10-4のイメージのとおり、変数first_nameに'Taro'が、変数family_nameに'Yamada'が設定されることになるのである。
◇ 丸括弧の省略
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。