Lesson 7 関数 ― Python基礎文法入門:機械学習&ディープラーニング入門(Python編)
Python言語の文法を、コードを書く流れに沿って説明していく連載。今回は、プログラム内の各処理を実現する関数について説明する。また、関連事項として、文字列フォーマット関数についても言及する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
ここまでの連載では、Lessson 4で変数を、Lesson 5・6(前回)でデータの型を説明した。今回は、Pythonプログラミングの基本中の基本で、文法の中で「変数」の次に大事である「関数」の利用方法について解説する。「関数」の定義方法については、次回Lesson 7で紹介する。※脚注や図、コードリストの番号は前回からの続き番号としている。
本連載は、実際にライブラリ「TensorFlow」でディープラーニングのコードを書く流れに沿って、具体的にはLesson 1で掲載した図1-a/b/c/dのサンプルコードの順で、基礎文法が学んでいけるように目次を構成している。関数については、利用頻度が非常に高い。具体的には、そのすべての図内のコードで使われており、割合で言うと63%の行数と広範にわたっている。すべての関数を詳しく説明する必要はないので、まず本稿の前半では、図1-aに「関数」が登場する初出の1行のみを取り上げる。本稿の後半では、「さまざまな関数の使用例」というタイトルでそれ以外の関数の使用例をコードの意味紹介とともに提示するにとどめる。
なお、本稿で示すサンプルコードの実行環境については、Lesson 1を一読してほしい。
Lesson 1でも示したように、本連載のすべてのサンプルコードは、下記のリンク先で実行もしくは参照できる。


Python言語の基礎文法
これまでの連載の中で何度か言葉だけが登場して具体的な解説を先伸ばしにしてきた「関数」について説明していこう。
関数の利用
関数(Function)は、何らかの処理、例えば変換や、計算、操作などを行う機能を持つ。
例えば、図1-aにある初出の「関数」のコードを見ると、リスト10-1のようになっている。
#import tensorflow as tf
#mnist = tf.keras.datasets.mnist
# 以下のコードを動かすためには、上記2行を事前に実行しておく必要がある
#---------------------------------------------------------------------
(x_train, y_train),(x_test, y_test) = mnist.load_data()
このコードについては、前回Lesson 6(リスト8-9)で、=の左辺が「タプル」で、右辺が「関数」だと説明済みである。今回は、この関数の内容について、より詳しく見ていく。
まず、このmnistは(Lesson 2で説明したとおり)モジュールである。復習すると、.は「<モジュール階層>の中の……」という意味だった。それに続くload_data()の部分が関数である。つまりこのコードは、mnist<モジュール階層>の中にあるload_data()関数を呼び出しているというわけだ。
なお、「load_data」という名前から推測すると、この関数は「データを読み込む(=ロードする)」という処理機能を持つ、と考えられるだろう。Lesson 3に倣ってAPIリファレンス「tf.keras.datasets.mnist.load_data」を調べてみると、「MNISTデータセットをロードする(Loads the MNIST dataset.)」と記載されている。MNISTデータセットとは、ディープラーニングの教材としてよく使われている手書き文字画像集である(※MNISTやデータセットという用語については、『機械学習&ディープラーニング入門(概要編)』のLesson 3を参照してほしい)。
実際にコードが実行されてload_data()関数が呼び出されると、その関数内部の処理(=MNISTデータセットをロードする)が実行され、その結果の値が返される。その値のことを戻り値(もどりち)もしくは返り値(かえりち)と呼ぶ。
関数は「関数内部で処理実行 → 結果出力」という流れで動作する文法機能と言えるが、戻り値はその結果出力に相当する。
この例では、入れ子構造のタプル値が返される(=出力される)ので、それをx_train/y_train/x_test/y_testという4つの変数にアンパック代入している、と前回説明済みだ。
確認のため、以上の内容をこれまで同様にイメージで表すと、図11-1のようになる。なお、入れ子構造の4つの変数は、シンプルにするため1つの箱にまとめて表現したので注意してほしい。

関数の呼び出し方について見ていこう。
関数の呼び出し方
関数の呼び出し方法(基本)を図解したのが図11-2である。ここでの関数名は、仮にsome_function()とした。

関数を呼び出すには、関数名(例えば「load_data」)の最後に丸括弧()を付ける、という特徴がある。この丸括弧()の中にあるarg1やarg2などは引数(arguments、ひきすう)と呼ばれる。
ちなみに引数は、仮引数(パラメーター:parameter)と実引数(arguments)に分ける場合もあるが、用語の使い分けが非常に紛らわしく、かつ使い分ける必要性もあまりない。よって、「引数」という用語だけを覚えておき、「パラメーター」も同じ「引数」だと忘れないようにしておけば、実用上の問題は起きないだろう。
関数がどんな引数を受け取るかは、関数を作成した人が定義する。例えば図11-2では、arg1やarg2……という複数の引数が定義されている(※これら関数定義時の引数のことを「パラメーター」や「仮引数」と呼ぶ)。
関数を呼び出す際には、これらのarg1やarg2……の場所に、数値や文字列値といったデータや値をそのまま記述するか、何らかのオブジェクトが格納された変数の名前などを記述する(※これら関数使用時の引数のことを「実引数」と呼ぶ)。
まとめると、関数は「(値入力) → 関数内部で処理実行 → 結果出力」という流れで動作する文法機能であり、引数はその値入力に相当するものである。
「基本」とした引数ありの関数の呼び出し以外に、引数が0個(=なし)という場合も多い(図11-3)。先ほどのload_data()関数も引数なしのパターンだ。

また、戻り値がないパターンもある(図11-4)。この場合、関数の処理だけを実行することになる。戻り値がない代わりに、画面出力など別の形で処理結果を示すことが多い。
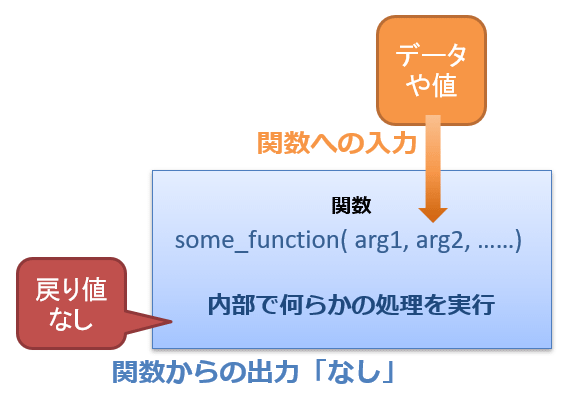 図11-4 関数を呼び出す方法(戻り値なし)
図11-4 関数を呼び出す方法(戻り値なし) 組み合わせを考えると次の4パターンがあり得る。
- 引数あり、戻り値あり、の関数
- 引数あり、戻り値なし、の関数
- 引数なし、戻り値あり、の関数
- 引数なし、戻り値なし、の関数
なお、戻り値があっても、変数に代入しないで実行することも可能だ(リスト10-2)。
mnist.load_data()
# 戻り値は出力(=表示)されるのみで、変数に保存されない
【コラム】print関数 vs. オブジェクト評価の自動出力
Python言語で、オブジェクトの中身を出力したい場合、基本的にはprint()関数を使用する。print()関数は、Python言語に標準で用意されている組み込み関数(Built-in functions)なので、何もインポートしなくても利用できる。実際に使うには、このprint()関数の引数に、オブジェクトや変数名を指定すればよい。リストex2は、その利用例である。
print(y_train)
# [5 0 4 ... 5 6 8] のようにシンプルに出力される
しかしここまでの連載では、そのprint()関数を使わず、変数の名前のみを記述することで、その変数に代入されているオブジェクトの中身を出力してきた。これは、本連載が前提としているGoogle Colabのようなインタラクティブシェルを用いた実行環境でのみ活用できる、「オブジェクト評価の自動出力」という機能である(※バッチ処理などで使う.pyファイルに記述したコードを実行する方法では、このようなオブジェクト評価の自動出力は行われない)。
オブジェクト評価の自動出力とは、リストex3のように、変数名(厳密には式:expression)だけの文を書いても、print()関数と同じような出力が自動的に表示される機能のことである。
y_train
# array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)のように出力される
ただし、自動出力機能とprint()関数の出力はまったく同じとは限らない。自動表示の場合は、あくまで式の評価結果(=開発やデバッグのために得る情報)が出力されているのに対し、print()関数の場合は、人が見るために綺麗に整形された情報が出力される、という違いがある。
具体的には、リストex2のprint()関数の出力は、シンプルで見やすい。一方、リストex3の自動出力機能の出力には、「array()」(=配列)などとより細かい情報が表示されている。開発時やデバッグ時には、むしろより多くの情報が表示された方がありがたいケースも多々あるので、どちらの出力がより好ましいかは状況により異なるだろう。
要は適材適所で使い分けるのがお勧めだが、本連載では、基本的には自動出力機能で、print()関数を使うべきところでのみprint()関数で記述していく。
自動出力機能についてより詳しく知りたい場合は、『機械学習&ディープラーニング入門(データ構造編)』[Lesson 1]の「【コラム】インタラクティブシェルにおけるオブジェクト評価の自動出力」にも説明を書いているので、併せて参照してほしい。
さまざまな関数の使用例
以上で関数の利用や呼び出し方の基本については、解説したことになる。
関数の利用の解説としては、ここで終わりにしてもよいが、図1-a/b/c/d内には多数の関数のコードが含まれている。そこで以下では、「使用例」という形でコードを提示し、必要最小限で説明していくことにする。コードの掲載は長くなるが、同じことの繰り返しなので、軽く読み流すだけでも十分である。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。